출처 : Core ML and Vision: Machine Learning in iOS 11 Tutorial
iOS11에서 새로이 업데이트 되는 머신러닝 기술인 Core ML과 Vision을 활용하는 적절한 튜토리얼이 있어 번역하며 공부해본다.
이 튜토리얼은 Xcode 9 Beta 버전 그리고 Swift4 와 iOS11 에서 정상작동한다.
머신 러닝의 인기가 대단하다. 많은 사람들이 그것에 대해 들어보았겠지만, 정확히 무엇을 이야기하는지 아는 사람은 그리 많지 않다. 이 튜토리얼은 Core ML과 Vision이라는 iOS11에서 처음 수개 된 프레임워크에 대해서 설명하고 있다. 특히 이미지의 장면을 분석하기 위해 Places205-GoogLeNet이라는 모델의 API를 활용하는 방법을 배울 수 있다.
시작하기
우선 기본 프로젝트를 다운로드한다. 기본 프로젝트는 이미 사진첩에서 이미지를 가져와 인터페이스에 표시해주는 기능을 갖고 있다. 따라서 당신은 머신러닝과 비전 기능을 구현하는 데 집중할 수 있다.
프로젝트를 빌드하고 실행하면 다음과 같이 도시의 밤 풍경과 버튼을 확인할 수 있다.
버튼을 클릭하고, 사진첩에서 다른 이미지를 선택해보자. info.plist에 이미 Privacy - Photo Library Usage Description 항목이 있기 때문에 문제 없이 사진첩에 접근할 수 있다.
이미지와 버튼 사이에는 이미지의 분석 결과를 표기하게 될 라벨이 있다.
iOS 머신 러닝
머신러닝은 컴퓨터가 명시적으로 프로그래밍 되지 않고 스스로 ‘학습’을 하는 인공지능의 유형이다. 알고리즘을 코딩하는 대신에 머신러닝을 사용하면 컴퓨터가 대용량의 데이터에서 패턴을 찾아 알고리즘을 개발하고 개선할 수 있다.
딥러닝
1950년대 이래로 인공지능 연구자들은 머신러닝에 대한 많은 접근방법을 개발해왔다. 애플의 Core ML 프레임워크는 신경망, 트리앙상블, 서포트 벡터 머신, 일반 선형 모델, feature engineering 및 파이프라인 모델을 지원한다. 인공지능은 2012년 구글이 유튜브 동영상을 이용해 인공지능을 훈련하여 고양이와 사람을 인식하는 것에서 시작하여 최근 수많은 성공사례를 만들어내고 있다. 시리와 알렉사와 같은 앱도 신경 네트워크의 발전 덕분에 가능해졌다.
신경망은 서로 다른 방식으로 연결되어있는 노드의 레잉로 인간 두뇌의 작동 방식을 모델링하려고 한다. 각 추가 레이어는 컴퓨팅 자원의 큰 향상을 요구한다. 개체 인식 모델인 Inception v3은 48개의 레이어와 약 2천만개의 파라미터를 포함하고 있다. 그러나 게산은 기본적으로 행렬 곱셈으로 이루어지며, GPU가 이러한 계산을 매우 효율적으로 수행한다. GPU 가격의 하락 덕분에 많은 사람들이 멀티레이어 신경망을 만들 수 있게 되었고, 이러한 멀티레이어 신경망을 이용한 학습을 딥러닝이라고 한다.
신경망 학습은 많은 양의 훈련 데이터를 요구하는데, 인터넷의 발전으로 인한 사용자 직접 생성 데이터의 폭증이 머신 러닝 르네상스에 기여했다. 모델 학습은 신경망에 학습 데이터를 입력하고 출력을 만들어내기 위해 파라미터들을 결합하는 수식을 도출해내도록 하는 것을 의미하며, 보통은 GPU가 많은 컴퓨터에서 수행한다. 학습 된 모델에 새로운 데이터를 입력하고 모델은 출력값을 계산해 내는데, 이를 추론이라고 한다. 추론 또한 입력값에서 산출물을 도출해내기 위해 많은 컴퓨팅이 필요하며, 애플의 Metal과 같은 프레임워크를 이용하면 스마트폰에서도 이러한 계산을 수행할 수 있게 된다. 이 튜토리얼의 마지막에서 볼 수 있듯이 딥러닝은 완벽하지 않다. 모든 표본을 대표할 수 있는 학습표본을 만들어내는 과정이 쉽지 않기 때문이다.
애플이 제공하는 것
애플은 iOS5에서 자연어 분석을 위한 NSLinguisticTagger를 발표했다. iOS8에서는 기기의 GPU에 낮은 레벨의 접근이 가능하도록 해주는 Metal 프레임워크를 발표했다. 지난 해(2016)에는 BNNS(Basic Neural Network Subroutines)를 Accelerate 프레임워크에 추가하여 개발자가 추론을 위한 신경망을 구축할 수 있도록 했다. 그리고 올해, 애플은 Core ML과 Vision을 가져왔다.
- Core ML은 당신의 애플리케이션에 학습된 모델을 아주 쉽게 사용할 수 있도록 해준다.
- Vision을 사용하면 얼굴, 랜드마크, 텍스트, 사각형, 바코드 및 다양한 객체를 감지하는 애플의 모델을 사용할 수 있다.
이 튜토리얼을 통해 두 가지를 모두 사용해 볼 수 있다. 이 두 프레임워크는 Metal을 기반으로 하여 장치 내에서 효율적으로 수행되기 때문에, 별다른 서버통신이 필요없다.
Core ML 모델을 앱과 통합하기
이 튜토리얼은 Places205-GoogLeNet 모델을 사용하며, 모델은 이곳에서 다운로드 받을 수 있다. 스크롤을 내려 Places205-GoogLeNet를 다운로드 받으면 된다.
만약 Caffe, Keras 혹은 scikit-learn등을 이용해 생성된 모델을 사용하고 싶다면 다음을 확인하면 된다: Converting Trained Models to Core ML
프로젝트에 모델 추가하기
GoogLeNetPlaces.mlmodel 을 다운로드 받았다면, Project Navigator의 Resource 그룹에 드래그&드롭 하면 된다.
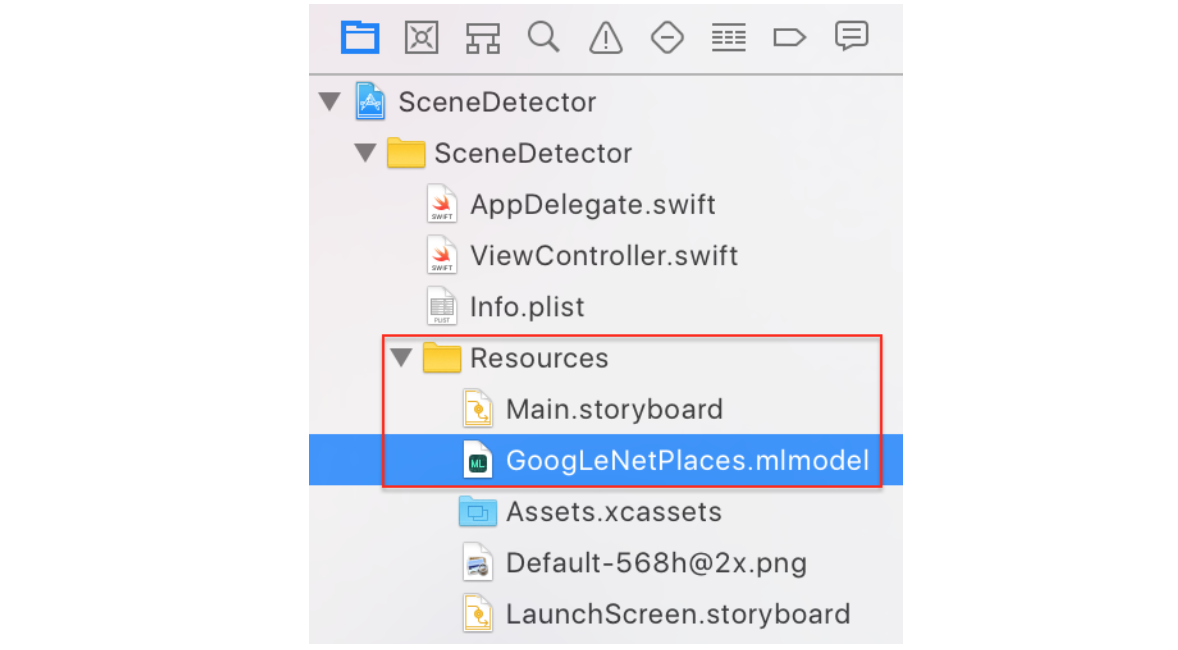
이 파일을 선택하고 잠시 기다리면 Xcode에서 생성한 모델 클래스를 확인할 수 있는 화살표가 나타난다. 만약 나타지 않는다면 우측메뉴에서 타겟을 추가해주면 된다.
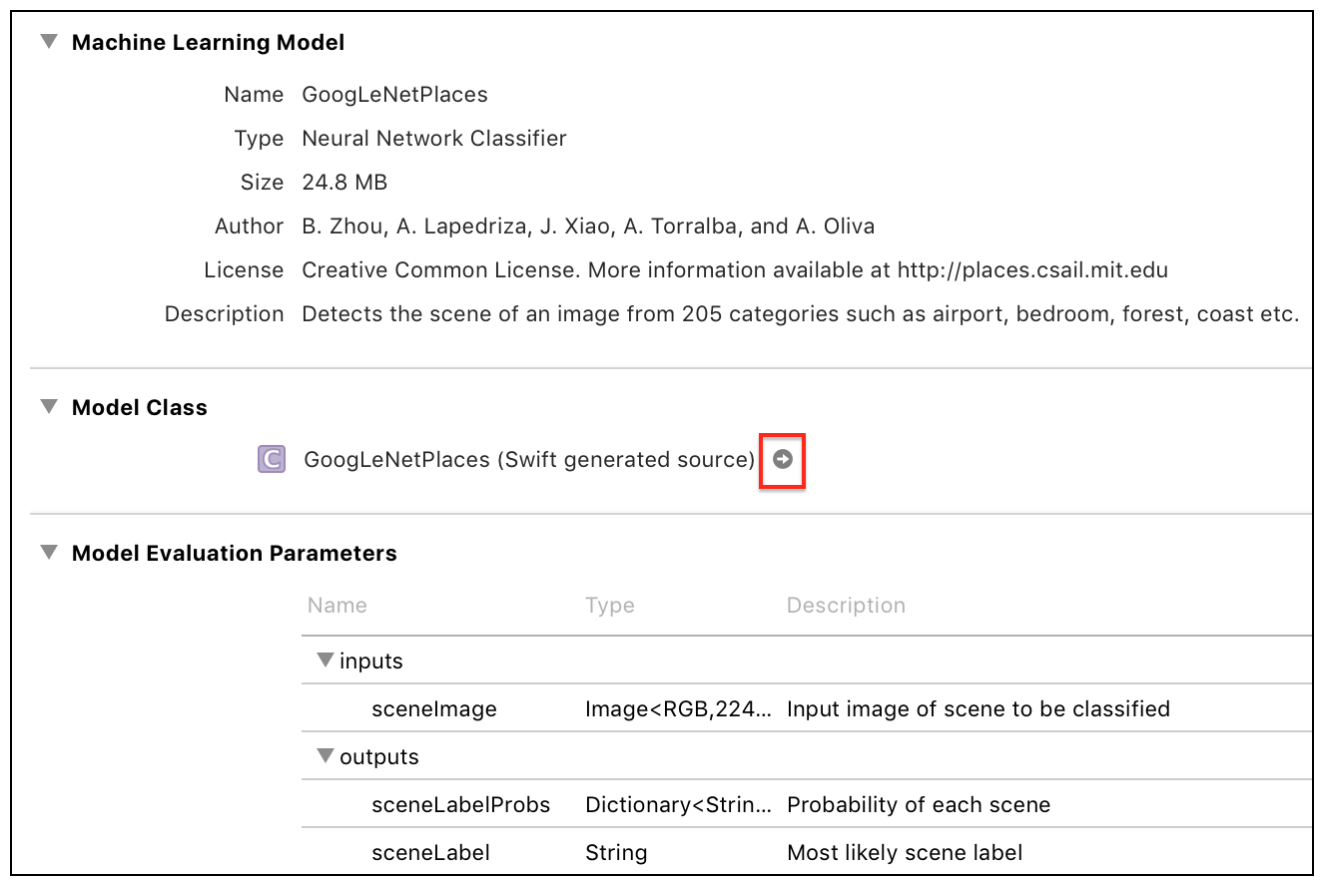
화살표를 클릭하면 모델 클래스를 확인할 수 있다.
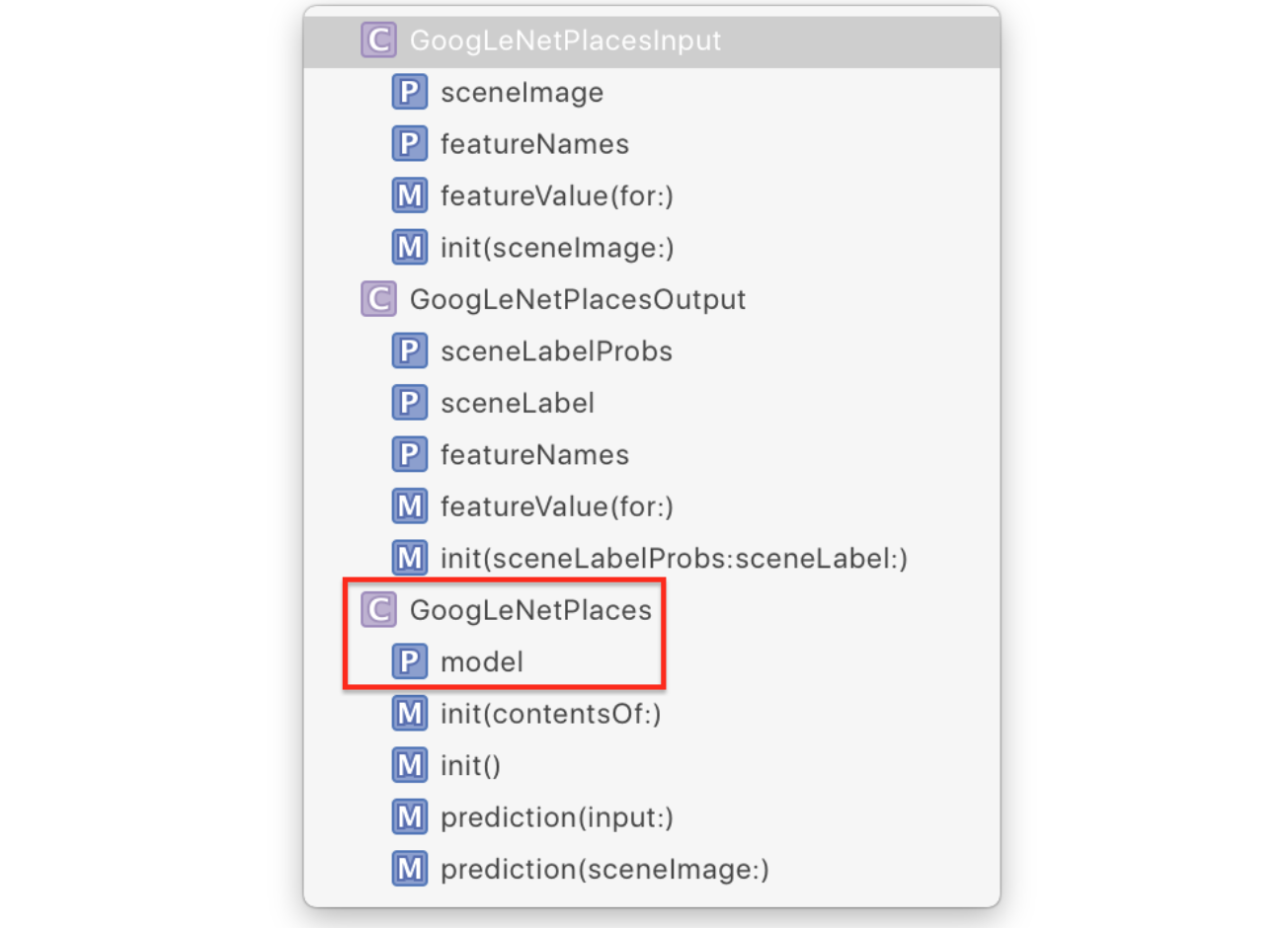
Xcode가 생성한 클래스와 메소드들을 확인할 수 있다. GoogLeNetPlacesInput은 sceneImage라는 CVPixelBuffer 타입의 변수를 가지고있다. 처음 보는 타입이지만 Vision프레임워크가 알아서 처리해 줄 것이기 때문에 걱정할 필요가 없다.
Vision 프레임워크는 GoogLeNetPlacesOutput의 속성을 results타입으로 변환해주고 예측 메소드 호출을 관리해주므로, 우리가 사용할 코드는 모델의 속성부분밖에 없다.
Core ML 모델을 Vision Model로 래핑하기
드디어 코드를 손으로 쓸 때가 왔다. ViewController.swift 파일을 열고 최상단에 CoreML과 Vision을 import 해준다.
import CoreML
import Vision
이어서 IBActions extension 이래에 다음 extension을 추가해준다
// MARK: - Methods
extension ViewController {
func detectScene(image: CIImage) {
answerLabel.text = "detecting scene..."
// Load the ML model through its generated class
guard let model = try? VNCoreMLModel(for: GoogLeNetPlaces().model) else {
fatalError("can't load Places ML model")
}
}
}
먼저 사용자에서 무언가 진행되고 있다고 알려주기 위한 메세지를 화면에 표시한다. 이어서 GoogLeNetPlaces를 초기화 할 때 에러를 발생시킬 수 있으므로 try를 사용해 모델을 생성해준다. VNCoreMLModel은 Vision 요청에 CoreML을 사용할 수 있도록 해주는 컨테이너다.
Vision의 표준 워크플로우는 모델을 생성하고, 하나 이상의 요청을 생성한 뒤, 요청 핸들러를 생성 및 실행시키는 방식으로 진행된다. 방금 모델을 생성했으므로, 요청을 생성시킬 차례다.
다음 라인을 detectScene(image:)의 마지막 라인에 추가해준다.
// Create a Vision request with completion handler
let request = VNCoreMLRequest(model: model) { [weak self] request, error in
guard let results = request.results as? [VNClassificationObservation],
let topResult = results.first else {
fatalError("unexpected result type from VNCoreMLRequest")
}
// Update UI on main queue
let article = (self?.vowels.contains(topResult.identifier.first!))! ? "an" : "a"
DispatchQueue.main.async { [weak self] in
self?.answerLabel.text = "\(Int(topResult.confidence * 100))% it's \(article) \(topResult.identifier)"
}
}
VNCoreMLRequest는 Core ML 모델을 사용하여 작업을 수행하는 이미지 분석 요청이다. Complete Handler는 request와 error 객체를 수신한다.
request의 result가 VNClassificationObsevation객체로 이루어진 배열인지 확인한다. 이 객체는 Core ML 모델이 예측자 혹은 이미지 프로세서가 아닌 분류자(Classifier)일 때 Vision 프레임워크에서 반환하는 타입의 객체이다. GoogLeNetPlaces 모델은 하나의 기능, 즉 이미지의 분류를 예측하기 때문에 분류자로 구분된다.
VNClassificationObservation는 두 속성을 갖는다: identifier(String타입)과 confidence(0~1사이의 숫자). 객체 이닉 모델을 사용하면 30%와 같은 특정 임계값 보다 confidence가 높은 하나의 결과값만을 볼 수 있다. 그런 다음 가장 높은 confidence를 갖는 첫번 째 결과를 취한다.
마지막으로 라벨을 업데이트 하기위해 메인 큐에 값을 전달하게 된다.
이제 세번째 순서: 요청 핸들러 생성 및 실행이다. 다음 라인을 detectScene(imgae:)의 마지막 라인에 추가해준다.
// Run the Core ML GoogLeNetPlaces classifier on global dispatch queue
let handler = VNImageRequestHandler(ciImage: image)
DispatchQueue.global(qos: .userInteractive).async {
do {
try handler.perform([request])
} catch {
print(error)
}
}
VNImageRequestHandler는 Vision 프레임워크의 표준 요청 핸들러이다.(비단 Core ML 모델에만 국한된 것은 아니다.) detectScene(image:)에서 전달 받은 이미지를 입력받은 뒤 perform 메소드를 호출하여 요청 배열을 전달 후 핸들러를 실행한다. 이번 예시에서는 하나의 요청만이 존재한다.
이미지 분석을 위해 모델 사용하기
이제 detectScene(image:)메소드를 두 장소에서 호출해주기만 하면 된다. 다음 라인을 viewDidLoad()의 마지막 줄 그리고 imagePickerController(_: didFinishPickingMediaWithInfo:)의 마지막줄에 추가해준다.
guard let ciImage = CIImage(image: image) else {
fatalError("couldn't convert UIImage to CIImage")
}
detectScene(image: ciImage)
이제 빌드 후 실행시켜 주면 분석 결과를 확인해볼 수 있다.
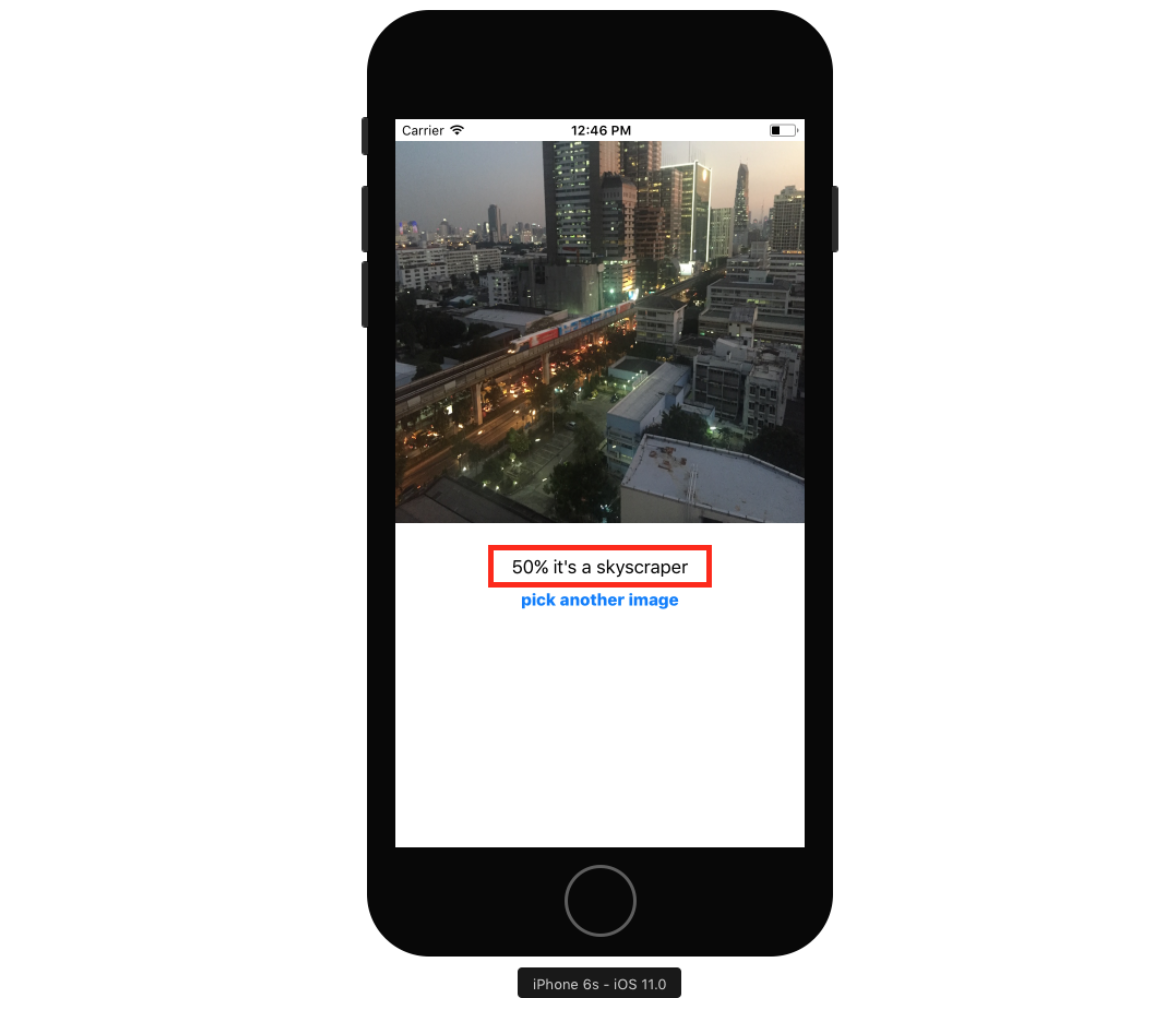
사진첩에서 다른 사진들을 불러와서도 확인해볼 수 있다. 다만 아직 모델이 완벽하지 않기 때문에 완벽한 결과를 반환하지는 않는다.